LDI Power BI How-To: Manage Table Relationships

Role of relationships
Once we have created our fact and dimension tables in the query editor, we then define the table relationships in the relationships pane of Power BI, either by dragging a field in one table over the top of another one or by selecting ‘Manage Relationships’ in the modelling tab:

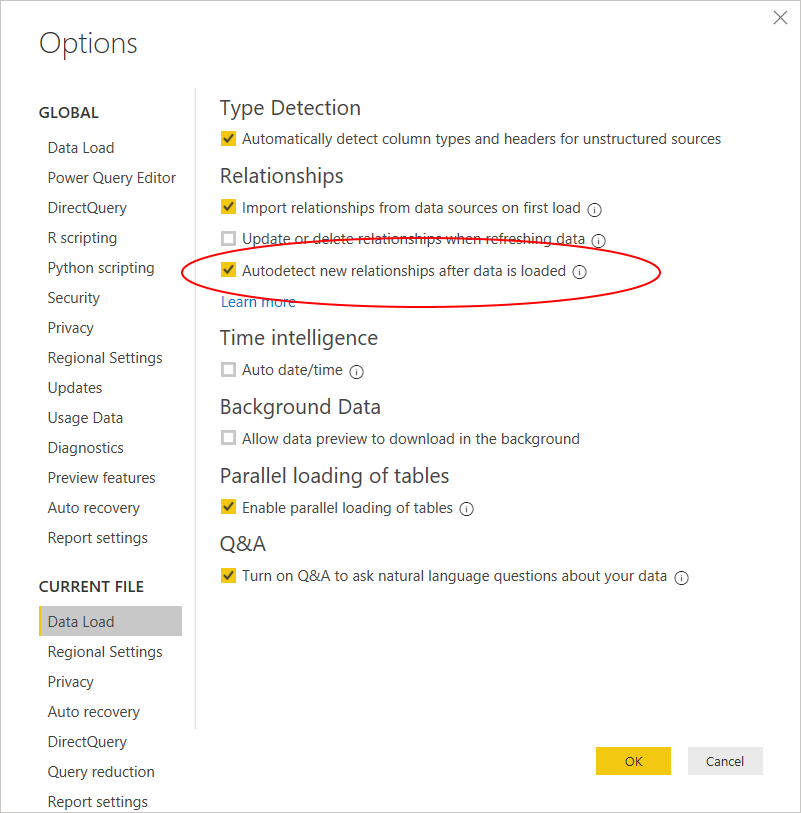
By default, Power BI will try to automatically create relationships between columns of the same name. This can save some time when the relationships are obvious, though can also potentially be dangerous (e.g. when there are multiple columns called ‘ID’ that don’t relate to each other!).
This default behaviour can be turned off for each individual file under File -> Options -> Data Load. If you forget to do this for a file, make sure you check the relationships once data is loaded rather than just assuming that they’re correct.
Relationships in Power BI work like a lookup in Excel although, rather than bringing all the reference data fields physically into the same table, they are kept in separate tables with the relationship defining which field from each table is used for this lookup.
These relationships are so important because they determine the flow of data model filters that are applied in our calculations (although these can be changed/overridden using DAX).
Consider the data model below and the scenario where we want to apply a filter to the product table (say filtering on a product colour). Some of the ways this could be achieved in Power BI include:
- Passing the colour into a filter condition in a DAX formula e.g. CALCULATE
- Selecting an element in a graph (with colour on the axis)
- Choosing the colour in a visual/page/report level filter
- Selecting a colour in a slicer
- Hovering over an element in a graph (with colour on the axis) that has a report tooltip
- Drilling through on colour to a separate drill-through page
Whichever way we apply this filter, a simple measure such as Sum(Sales[Sales Amount]), based on the sales table, will then reflect this filter condition showing sales only for the colour(s) selected.

The sheer number of ways in which filters can be applied to a given table or visual make it extremely important to ensure that the data model and the relationships are simple. Adding complexity to the data model often means that more complex DAX is required in order to navigate it, and there is a much higher chance that your visuals will show incorrect numbers when some filters are applied by the end user.
The star schema – one or more central fact tables surrounded by dimension tables – is most often the best choice for how to model your data and if you have done this the relationships between tables are straight forward.
In our sales example, the fact sales table represents one row per sale and contains a field for the sales amount along with fields containing the keys/ids for the corresponding dimensions (e.g. product, customer):

We can create relationships between the keys in the fact table and the various dimension tables. These are 1:many relationships – 1 row in the dimension table per entity relates to many rows in the fact table). The resulting schema then looks like:

There are no relationships between the dimension tables, only between the dimensions and the fact table. This star schema makes the data model easy to understand, faster (as you filter on the dimension tables which are typically much smaller) and is well suited to a Power BI model.
Whilst one:one and one:many relationships have historically been the only relationships type available in Power BI, it is now possible to have a relationship type as many:many. However, this should be exercised with caution because it can create ambiguity and slower performance. This is discussed in the topic Work with data at different grains.

Relationship Options
When creating a relationship between two tables there are a few options which can be set:
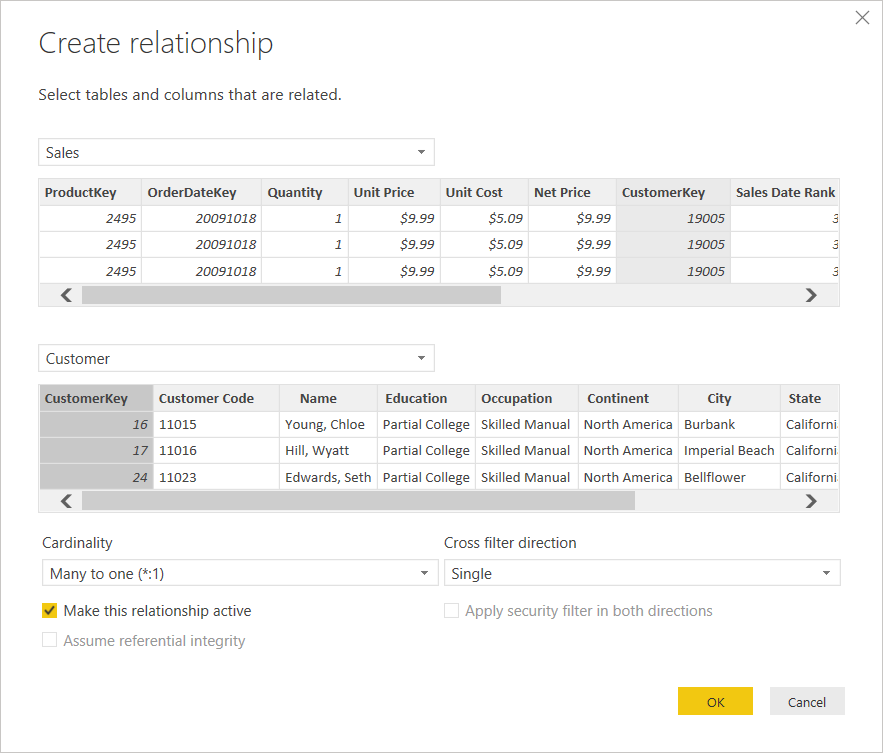
The first step is to choose the single column from each table which forms the basis for the relationship. Whilst a merge in the query editor can be based on multiple columns, in the data model a relationship can only be based on one column from each table.
Where there isn’t a single column in the dimension table that uniquely identifies each row, you can create a surrogate key column either by using an index column in the query editor and merging it back in the fact table, or by creating a calculated column in the data model in both the dimension and fact table to join on.
This latter method is shown in the video below using the DIAD example. Whilst Zip codes are unique within a country, the same zip code is present in multiple countries and therefore the Geography dimension table does not contain a column that uniquely identifies each row. The column which uniquely identifies each row is then created by combining the Zip and Country columns in both the Geography and Sales tables:

This example uses a calculated column in DAX, though it is generally better to do this in the query editor instead. In the query editor, the zip code and country columns can then be removed from the fact table before the data is loaded into the data model, leaving just one column rather than three. Reducing the number of columns loaded, particularly those in a fact table across a large number of rows, will improve performance and make the model simpler.
Once the column from each table has been selected, the cardinality (one:one, one:many, many:one or many:many) will auto-select depending on whether neither, one or both of the tables contains unique values across the column selected. You will not be able to select a relationship cardinality where this does not match the uniqueness of rows across the columns selected.
Note that one:many is the same thing as many:one; how it is described is determined by which table was selected at the top and which at the bottom in the New Relationship dialog.
Many:Many relationships should be avoided as a general rule. If you are expecting unique values in a dimension table column though this is not being recognised by the engine, then there may be unexpected duplicates or blanks. To check this, select the dimension table column in the data pane and check that the number of distinct values (shown at the bottom underneath the data table) is the same as the total number of values:
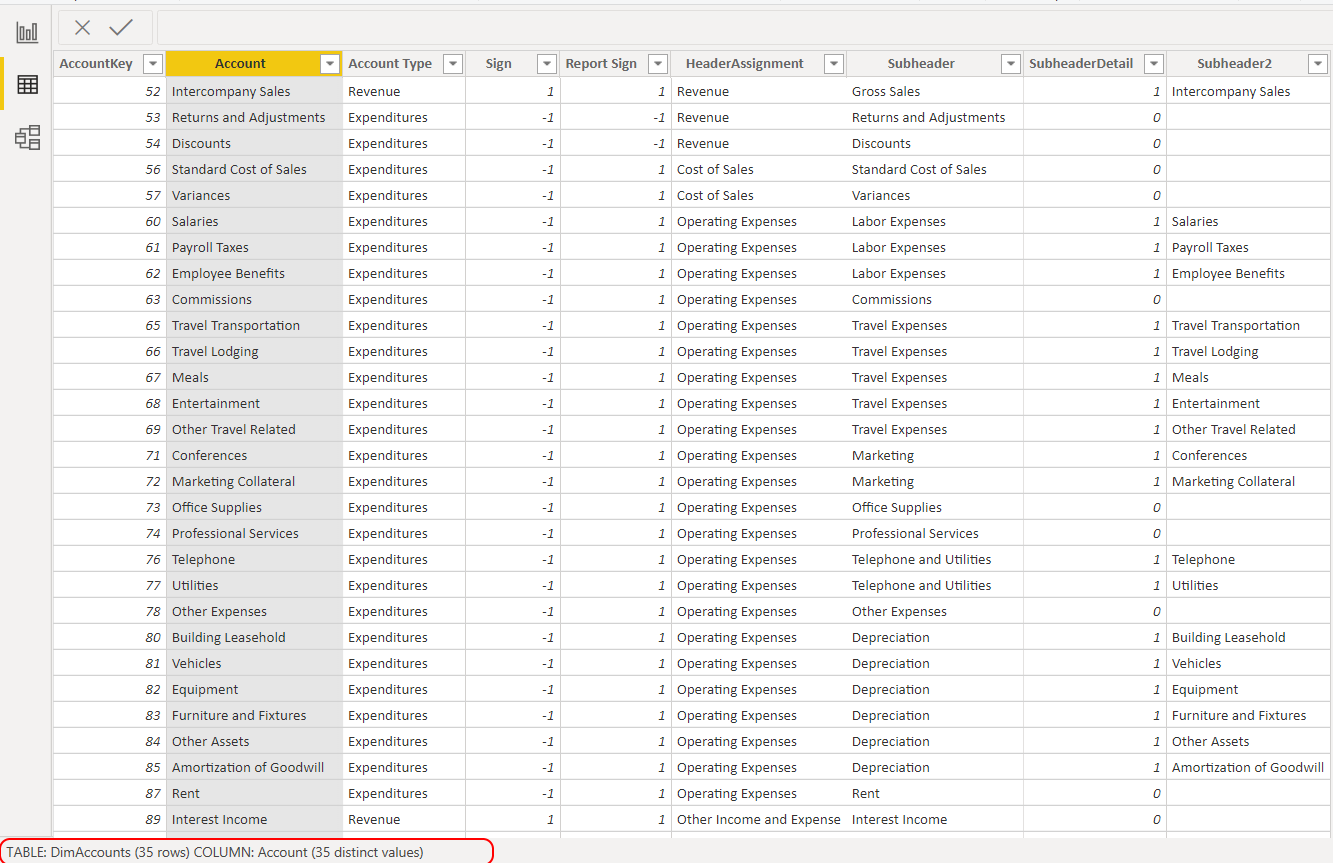
To see which rows are duplicated, go back to the table in edit queries and add a temporary step to ‘Keep Duplicates’. Blanks can also be removed from here:

Going back to the create relationship dialog, the cross filter direction – single or both – determines whether the filter in a one:many relationship can flow in one direction (from the one side to the many side) or both ways. This is discussed in the section below.
Underneath the Cardinality/Cross filter drop down selections, there are three check boxes that can be toggled on or off:
• Make this relationship active: Where there are no existing relationships between the two tables (direct or indirect) then the relationship can be marked as active. Where there is already a relationship then any additional ones cannot be active. Inactive relationships are discussed in the section below. Note that you cannot mark the relationship as active if this will create ambiguity in the model – i.e. multiple paths for data to flow through. This is discussed in the section ‘Role Playing Dimensions’ below.
• Assume Referential Integrity: This option is available when connected to data via Direct Query as a way of improving performance. This is achieved by querying the data source using an inner join between the two tables in this relationship rather than a left join. A left join between the fact and dimension table is usually the safest in case there are key values in the fact table which don’t match to any dimension; in this case they will show as null’ for that dimension value though with an inner join those fact table rows would be removed. However, if you are confident in the data integrity of the ETL/Data warehousing processes so that all the fact dimension values will match a value in the dimension table then utilising an inner join by selecting this option will improve performance.
• Apply security filter in both directions: Even with a bi-directional relationship enabled, a Row Level Security filter will be treated as single-directional by default. The reason for this is that by applying a filter one on dimension for a role, you might not automatically want to filter other dimensions indirectly. For example, creating a RLS role for the Geography table so that people in a particular role can only see a specified region, you might not want to automatically also filter out products that were not sold in that region. Having this checkbox enabled will allow the RLS relationship to filter records based on a security filter and is particularly useful with Dynamic Row Level Security
Some tips for making the data model easier to understand:
- The dimension key fields in both the fact and dimension table should be hidden: right click and select ‘hide in report view’. These fields are just used for a relationship and, as they shouldn’t be used directly in a report, it is generally neater to hide them. Note that it is still possible to use these fields in a measure e.g. to perform a distinct count of IDs in the fact table.
- The relationship pane has tabs along the bottom for creating different views and this should be utilised. To create a new view, click on the + icon on the tabs, and drag tables in from the fields pane into the view. Where there are lots of tables and lots of relationships in the data model, this can help to view sets of tables/relationships separately; where there are multiple fact tables, each star (fact table with its corresponding dimension) should be represented in its own view to improve readability.

Relationship Direction
Relationships are usually only required to be single direction – data flows from the dimension tables (as slicers/axis of the charts or rows on the table) into the fact table.
It is also possible to enable bi-directional relationships between two tables – i.e. with data flowing from the fact table to the dimension as well. Note that you do not need bi-directional filters to filter by multiple dimensions at the same time on a single visual. For example, in the data model shown below, you can filter by product and then also cross highlight or drill down by date just by using single direction filters.
Creating single direction filters is always the safest option. Bi-directional filters create potential model ambiguity (see this article from SQL BI).
A scenario where people typically enable bi-directional filters is where you want to restrict the dimension values that are visible in a slicer; where there is a full list of all dimension values but you only want the users to select from ones for which data exists. As an example you might have a calendar table with all dates going out into the future, but you only want to show/have available to select only those dates which have sales data against them. You might also want cross-filtering to restrict slicer values – e.g. where you apply a filter for a specific customer and then want the product slicer to restrict to products purchased by that customer.
With recent updates to Power BI, however, this is no longer required: it is now possible to apply a visual level filter to a slicer. Therefore to show only dates that have sales against them, even when the calendar table contains future dates, you can apply a visual level filter for the Sales Amount measure not being blank:

Another scenario might be where you want to perform some calculation on the dimension based on another dimension value, e.g. to count the number of customers who bought a specific product. If your count of customers measures is based on the dimension table e.g.
NoOfCustomers =
COUNTROWS ( Customer )
then this will not work with single direction relationships. Data flows from the product dimension to the fact table but not then back from the fact table to the customer dimension unless the relationship is set as bi-directional.
However, we also have an alternative to bi-directional relationships in this scenario: using the fact table for your measure instead. By having the customer count measure instead as
NoOfCustomers =
DISTINCTCOUNT ( Sales[CustomerKey] )
This count will respond to any filter context applied as the fact table is being filtered by product and any other dimensions. Given that measures should generally always be applied against columns in a fact table anyway, this is likely to be a preferred approach.
Where bi-directional relationships are still required, it is possible (and somewhat safer) to enable it specifically for particular measures by using the CROSSFILTER DAX function. The arguments you pass into this are the left hand table/column (from the dimension table), the right hand table/column (from the fact table) and the filter direction you want (BOTH for bi-directional).
So the measure required for the above scenario would look like
No of Customers CrossFilter =
CALCULATE (
COUNTROWS ( Customer ),
CROSSFILTER ( Sales[CustomerKey], Customer[CustomerKey], BOTH )
)

Multiple Relationships Between Tables
As mentioned, there can only be one active relationship between two tables, i.e. only one column from each table can participate in the relationship.
But what about when there are multiple fields in your fact table which relate to a dimension? A good example might be with the calendar (date) table. There may be multiple dates in your fact table (e.g. order date, shipment date, return date) all of which could potentially have a relationship with the calendar table. It may be useful to analyse the number of sales over time, as well as the number shipments over time and the number of returns over time, all within the same report.
One possible solution to this is to create multiple relationships between the calendar table and the sales fact table, with the main one being the active relationship and any others being inactive (activated on demand using DAX in a measure).
This is represented in the below data model:


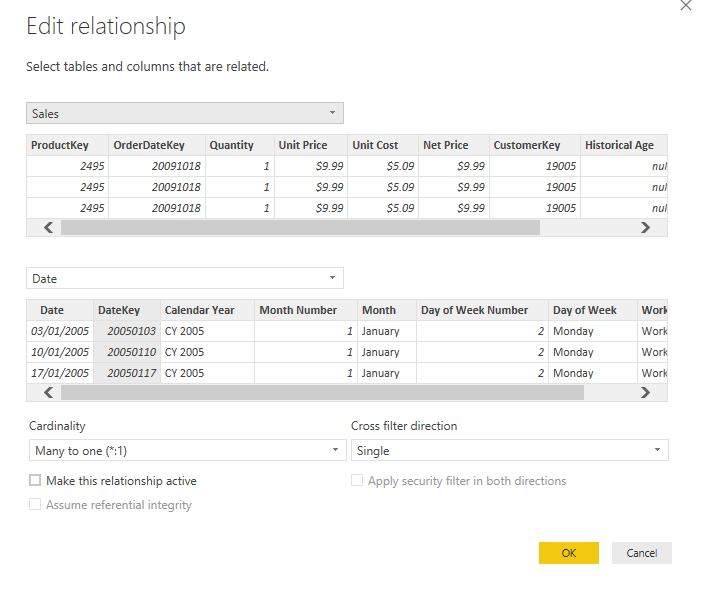
There are two relationships between the tables – the one between Order Date and DateKey is active whereas the one between Shipment Date and DateKey is marked as inactive (represented by the dotted line).
So any visuals or tables which use date attributes will be based on the order date by default – e.g. the measure COUNTROWS(Sales) against date from the date table on the axis will give you the number of orders placed on each date. If instead you wanted to know the number of orders shipped on each date, you would need to activate the relationship between DateKey and Shipment Date in the measure. This can be achieved using the USERELATIONSHIP function as the filter argument in a CALCULATE function e.g.:
# Orders Shipped =
CALCULATE (
COUNTROWS ( Sales ),
USERELATIONSHIP ( ‘Date'[DateKey], Sales[ShipmentDateKey] )
)
This will activate the relationship specifically for that measure, deactivating any others. In this way it is possible to have both measures (# Orders placed and # Orders shipped) against a single date axis.
This approach is shown in the video below:

An alternative to creating inactive relationships is to not actually have any relationships between these two tables in the data model but rather to keep them disconnected and create a virtual relationship on the fly as required in DAX measures.
The most intuitive DAX function for creating a virtual relationship is TREATAS, also used as an argument within CALCULATE. For this function you pass in the two columns that you want to create a relationship between, but you encapsulate the first one (in this case the date field from the date table) inside VALUES. So for example:
Sales Ordered =
CALCULATE (
[Sales Amount],
TREATAS ( VALUES ( ‘Date'[Date] ), Sales[Order Date] )
)
Utilising this approach is shown in the video below:

Which of these approaches should you choose? Whilst the data model looks neater not having dotted lines as inactive relationships, virtual relationships are considerably slower than physical ones. USERELATIONSHIP is still also a more familiar/better understood DAX function compared to TREATAS.
For these reasons, I tend to use inactive relationships but rather than having one active (default) relationship, I prefer to keep all the relationships as inactive and explicitly create measures for all of them.
Role Playing Dimensions
An alternative approach to dealing with the above situation is to have multiple calendar tables – e.g. an Order Date Table which links to the order date field in the Sales table, and a separate Shipping Date Table which links to the shipping date. Then, when you want to analyse by order date, you use the date attributes from the Order Date Table and when you want to analyse by shipping date you use the Shipping Date Table.
You can create a copy of a table by creating a new calculated table (Modelling -> New Table) and just referencing the original table. e.g. DateShipment = Date. It is also a good idea to change the attribute names so that they differ between the tables – e.g. rather than having the same field called ‘Year’ in both calendar tables, in the Order Date Table it could be called ‘Order Year’ and in the Shipping Date Table ‘Shipping Year’. This is shown as below:

This is known as a role-playing dimension: separate copies of dimension tables are used to play different roles (in this case order date vs shipment date). From a pure dimensional modelling perspective, this is the way that different dates should be modelled – each as their own dimension. The important consideration, however, is what makes sense from a business (rather than technical) perspective; whether having different date tables would be confusing to users or more intuitive. It also depends on the type of analysis that is required. For plotting sales ordered/shipped/delivered over a single date axis, the inactive/virtual relationship method makes sense. But it doesn’t allow the user to easily slice and dice by different dates – to see the profile of products shipped over time for all orders placed in a given month, measures will be much simpler having separate dimension tables.
Role playing dimensions is also often a potential solution to avoid model ambiguity. Consider the below example:

If the user puts the # Orders against City name, the engine is unclear whether it is supposed to return the # Orders for customers who live in a particular city (using the customer table flow) or the # Orders for stores located in that city (using the store dimension flow). Here Power BI has avoided ambiguity by making one of the relationships inactive.
One way to deal with this is to have geography as a role-playing dimension: One Geography table which connects to the Customer table (Customer Geography) and one to the Store table (Store Geography).
Yet another approach might be to take it from a snowflake schema into a star schema by de-normalising: i.e. bring the geography fields into the customer dimension table (calling them e.g. ‘Customer City’), and also bringing them into the store dimension (calling the fields e.g. ‘Store City’).
In this particular situation, denormalization makes the most sense as there are few attributes which are easy to distinguish and we are moving closer to a star schema. Taking this approach for the dates example above would involve adding several date attribute columns in the sales fact table e.g. Shipping Month, Shipping Year, Delivery Month, Delivery Year. Given the number of date attributes, and the desire to keep fact tables as thin as possible, this is unlikely to be an optimal solution for that scenario.

Relationship against a 'binning table'
It is often useful to bucket or group continuous numerical values into categories e.g. High/Medium/Low. This is a useful technique in data visualisation in order to distill a message from the sea of data – perhaps it matters very little whether a value is 50.5 or 50.7 from one day to the next but where you have 30% of values between 50-70 in one month which rises to 60% of observations the following month, then this potentially tells an interesting story.
Suppose we are interested in the age demographic of customers who purchase our products – e.g. the proportion of customers who are teenagers vs those who are elderly. We have Date of Birth as a field in the customer dimension table and whilst we can calculate how old they are today, it would be more accurate to consider their age as at the date of sale (In this way age could be considered a Slowly Changing Dimension). In this scenario, the most efficient way to deal with this would be to add a calculated column in the fact table to calculate the customer age:
Customer Age as at Sales Date =
VAR SalesDate = Sales[Order Date]
VAR CustomerDOB =
RELATED ( Customer[Birth Date] )
RETURN
DATEDIFF ( CustomerDOB, SalesDate, YEAR )
Now we have a whole range of ages in the field though again we’re not particularly interested in how many people buy our products who are aged 36 vs those who are aged 37, we’re more interested in their broad age category.
There are binning and grouping options available in the front-end layer of Power BI. We can right click on the Customer Age as at Sales Date field and create dynamic bins (e.g. group all ages into 10 bins, or bins of 15 years each) or we could manually create groups and assign each individual age to a group. However, this method could be considered quite cumbersome and the way that groups/bins are displayed in the visual layer are not the most intuitive.
An alternative to this is to create your own ‘lookup’ table which returns an appropriate label with additional columns to help with analysis (e.g. a sort order for the categories).
The age categories table might look something like:

The sort order doubles up as a surrogate key uniquely identifying each row, though the challenge is around how to create a relationship between the age column in our fact table and this lookup table. Using the From (or To) column wouldn’t give an error but it wouldn’t return the correct results – it would only show those customers who are at the exact age of the start/end of the category.
This is something that can potentially be solved in Power Query (see article here) though as part of this data modelling section, we will look at how we can create a calculated column in the fact table to bring in the age category we require.
An example of a calculated column which would give us the age category is:
Customer Age Category =
VAR CustomerAge = Sales[Customer Age as at Sales Date]
VAR AgeFilter =
FILTER (
AgeCategories,
CustomerAge >= AgeCategories[From ]
&& CustomerAge < AgeCategories[To ]
)
VAR BlankCustAge =
ISBLANK ( CustomerAge )
RETURN
IF (
BlankCustAge,
“N/A”,
CALCULATE ( VALUES ( AgeCategories[Age Category] ), AgeFilter )
)
As long as our lookup table is well structured in that there is no overlap between buckets (so a single age value can only ever belong to one bucket), then we can use FILTER to narrow down the required row of the lookup table and be confident that AgeCategories[Age Category] with the filter condition applied will return only one value.
Note that it isn’t possible to then create a relationship between this column and the Age Categories table. The relationship is implicit in the calculation so it creates a circular dependency. To work around this, either:
- Create a copy of the Age Categories table (Modelling -> New Table) which can be used in a relationship (hiding one or both of the tables in the report view), or
- Bring in any required additional attribute values (in this case perhaps Sort Order) as separate calculated columns in the fact table , using the same formula as above though changing the field that is referenced in the VALUES function.

Related Articles

Design a Data Model


Power BI How to build a star schema. This topic looks at how to understand what structure of data tables you need, and how to model them using a star schema When data is imported into Power BI, the resulting data model sits at its heart. It drives the kind of analysis that can be… Continue reading Design a Data Model
Read More
Example Reports
Power BI Example Reports | Visual Best practice design This report was the winner of the Complex Data Preparation Challenge for the 2017 Data Insight Summit in Seattle. The challenge involved taking a number of disparate data sets from the Hawaii Tourism Authority (on visitor numbers to Hawaii) and turning them into a visualization which… Continue reading Example Reports
Read More
Write Filter-based Measures
Power BI How-to: DAX | Use CALCULATE and FILTER to write Filter-based Measures The easiest way to understand the role of DAX Measures in Power BI is to think of them as advanced pivot table formulas that work in a slightly different way compared to standard formulas in the Excel grid. Power BI How-to: DAX… Continue reading Write Filter-based Measures
Read More